《Java核心技术卷一》第七章
第 7 章 异常、断言和日志
如果由于程序的错误或一些外部环境的影响,导致用户在运行程序期间做的所有工作统统丢失,这个用户有可能永远不会再使用这个程序了。为了尽量避免这类事情的发生,至少应该做到以下几点:
- 向用户通知错误;
- 保存所有工作;
- 允许用户妥善地退出程序。
对于异常情况,例如,可能造成程序崩溃的糟糕的输入数据,Java 使用了一种称为**异常处理(exception handling)**的错误捕获机制。
7.1 处理错误
假设在 Java 程序运行期间出现了一个错误。这个错误可能是包含错误信息的文件导致的,或者是网络连接出现问题造成的,也有可能(我真是不想提到这一点)是因为使用了非法的数组索引,或者试图使用一个还没有指定对象的对象引用。用户期望在出现错误时,程序能够采取合理的行为。如果由于出现错误而导致一个操作无法完成,程序应该返回到一种安全状态,并允许用户执行其他的命令,或者允许用户保存所有工作,并妥善地终止程序。
要做到这些并不是一件容易的事情。其原因是检测(或者甚至引发)错误条件的代码通常与那些能够让数据回滚到安全状态或者能够保存用户工作并妥善退出程序的代码相距很远。**异常处理的任务就是将控制权从产生错误的地方转移到能够处理这种情况的一个错误处理器。**为了在程序中处理异常情况,必须考虑程序中可能出现的错误和问题。那么需要考虑哪些问题呢?
- 用户输入错误。除了那些不可避免的键盘输入错误外,有些用户喜欢自行其是,而不遵守程序的要求。例如,假设有一个用户请求连接一个 URL,而提供的 URL 语法不正确。你的代码本应该检查语法,但如果没有检查,网络层就会报错。
- 设备错误。硬件并不总是让它做什么,它就做什么。打印机可能被关掉了。网页可能临时不能浏览。设备经常在完成任务的过程中出问题。例如,打印机在打印过程中可能没有纸了。
- 物理限制。磁盘已满,你可能已经用尽了所有可用内存。
- 代码错误。方法有可能没有正确地完成工作。例如,方法可能返回了一个错误的答案,或者错误地使用其他方法。计算一个非法的数组索引,试图在散列表中查找一个不存在的记录,或者试图让一个空栈执行弹出操作,这些都是代码错误的例子。
对于方法中的错误,传统的处理方法是返回一个特殊的错误码,由调用方法分析。例如,对于从文件中读取信息的方法,通常返回一个特殊值 -1(而不是一个标准字符)表示文件结束。这对于处理很多异常状况都是很高效的方法。还有一个表示错误状况的常用返回值是 null 引用。
遗憾的是,并不是任何情况下都能够返回一个错误码。有可能无法明确地区分合法数据与非法数据。一个返回整型的方法就不能简单地返回 -1 表示错误,因为 -1 很可能是一个完全合法的结果。
Java 允许每个方法有一个候选的退出路径,如果这个方法不能以正常的方式完成它的任务,就会选择这个退出路径。在这种情况下,方法不会返回一个值,而是抛出(throw)一个封装了错误信息的对象。需要注意的是,这个方法会立刻退出,并不返回正常值(或任何值)。此外,也不会从调用这个方法的代码继续执行,取而代之的是,异常处理机制开始搜索一个能够处理这种异常状况的异常处理器(exception handler)。
异常有自己的语法和一个特殊的继承层次结构。下面首先介绍语法,然后再给出一些提示,告诉你如何有效地使用这种语言特性。
7.1.1 异常分类
在 Java 程序设计语言中,异常对象都是派生于 Throwable 类的一个类的实例。稍后还会看到,如果 Java 中内置的异常类不能满足需求,用户还可以创建自己的异常类。
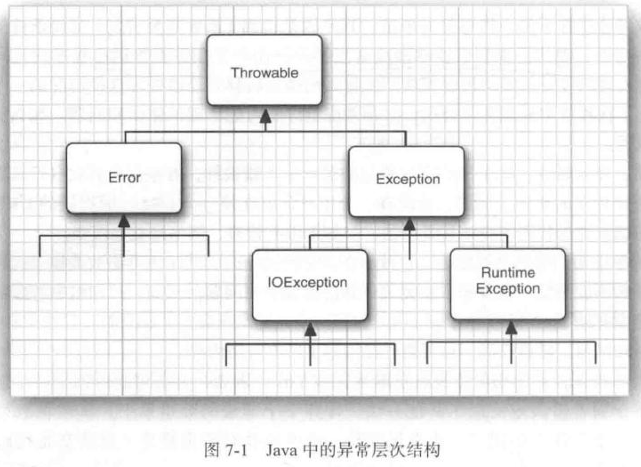
图 7-1 是 Java 异常层次结构的一个简化示意图。
需要注意的是,所有的异常都是由 Throwable 继承而来,但在这个层次结构中,下一层立即分为两个分支:Error 和 Exception。
**Error 类层次结构描述了 Java 运行时系统的内部错误和资源耗尽问题。**你不应该抛出这种类型的对象。如果出现了这样的内部错误,除了通知用户,并尽力妥善地终止程序之外,你几乎无能为力。
编写 Java 程序时,要重点关注 Exception 层次结构。这个 Exception 层次结构又分为两个分支:一个分支派生于 RuntimeException;另一个分支包括其他异常,不继承这个类。一般规则是:由编程错误导致的异常属于 RuntimeException;如果程序本身没有问题,但由于 I/O 错误之类的问题导致的异常属于其他异常。
继承自 RuntimeException 的异常包括以下问题:
- 错误的强制类型转换。
- 越界的数组访问。
- 访问
null指针。
不继承自 RuntimeException 的异常包括:
- 试图越过文件末尾继续读取数据。
- 试图打开一个不存在的文件。
- 试图根据给定的字符串查找
Class对象,而这个字符串表示的类并不存在。
“如果出现 RuntimeException 异常,那么一定是你的问题”。应该通过检测数组索引是否越界来避免 ArrayIndexOutOfBoundsException 异常;如果你在使用变量之前先检查它是否为 null,NullPointerException 异常就不会发生。
如何处理不存在的文件呢?难道不能先检查文件是否存在再打开它吗?嗯,这个文件有可能在你检查它是否存在之后就被立即删除。因此,“是否存在”取决于环境,而不只是取决于你的代码。
Java 语言规范将派生于 Error 类或 RuntimeException 类的所有异常称为非检查型(unchecked)异常,所有其他异常称为检查型(checked)异常。。编译器将检查你是否为所有的检查型异常提供了异常处理器。
7.1.2 声明检查型异常
如果遇到了无法处理的情况,Java 方法可以抛出一个异常。这个道理很简单:方法不仅需要告诉编译器将要返回什么值,还要告诉编译器有可能发生什么错误。例如,一段读取文件的代码知道读取的文件有可能不存在,或者文件可能为空,因此,试图处理文件信息的代码就需要通知编译器可能会抛出 IOException 类的异常。
要在方法的首部指出这个方法可能抛出一个异常,所以要修改方法首部,以反映这个方法可能抛出的检查型异常。例如,下面是标准类库中 FileInputStream 类的一个构造器的声明。
1 | |
这个声明表示这个构造器将根据给定的 String 参数生成一个 FileInputStream 对象,但也有可能出错而抛出一个 FileNotFoundException 异常。如果真的发生了这种糟糕的情况,构造器将不会初始化一个新的 FileInputStream 对象,而是抛出一个 FileNotFoundException 类对象。如果这个方法真的抛出了这样一个异常对象,运行时系统就会开始搜索知道如何处理 FileNotFoundException 对象的异常处理器。
编写你自己的方法时,不必声明你的方法可能抛出的所有 Throwable 对象。至于什么时候需要在所写的方法中用 throws 子句声明异常,以及要用 throws 子句声明哪些异常,需要记住在遇到下面 4 种情况时会抛出异常:
调用了一个抛出检查型异常的方法,例如,
FileInputStream构造器。检测到一个错误,并且利用
throw语句抛出一个检查型异常。程序出现错误,例如,
a[-1] = 0会抛出一个非检查型异常(这里会抛出ArrayIndexOutOfBoundsException)。Java 虚拟机或运行时库出现内部错误。
如果出现前两种情况,则必须告诉使用这个方法的程序员有可能抛出异常。为什么?因为任何一个抛出异常的方法都有可能是一个死亡陷阱。如果没有处理器捕获这个异常,当前执行线程就会终止。
有些 Java 方法包含在对外提供的类中,对于这些方法,应该通过方法首部的**异常规范(exception specification)**声明这个方法可能抛出异常。
1 | |
**如果一个方法有可能抛出多个检查型异常类型,那么就必须在方法的首部列出所有的异常类。每个异常类之间用逗号隔开。**如下面这个例子所示:
1 | |
但是,不需要声明 Java 的内部错误,即从 Error 继承的异常。任何代码都有可能抛出那些异常,而我们对此完全无法控制。
类似地,也不应该声明从 RuntimeException 继承的那些非检查型异常。
1 | |
这些运行时错误完全在我们的控制之中。如果特别担心数组索引错误,就应该多花时间修正这些错误,而不只是声明这些错误有可能发生。
总之,一个方法必须声明所有可能抛出的检查型异常,而非检查型异常要么在你的控制之外(Error),要么是由从一开始就应该避免的情况导致的(RuntimeException)。如果你的方法没有诚实地声明所有可能发生的检查型异常,编译器就会发出一个错误消息。
当然,从前面的示例中可以知道:不只是声明异常,你还可以捕获异常。这样就不会从这个方法抛出这个异常,所以也没有必要使用 throws。
⚠ 警告:如果在子类中覆盖了超类的一个方法,子类方法中声明的检查型异常不能比超类方法中声明的异常更通用(子类方法可以抛出更特定的异常,或者根本不抛出任何异常)。特别需要说明的是,**如果超类方法没有抛出任何检查型异常,子类也不能抛出任何检查型异常。**例如,如果覆盖
JComponent.paintComponent方法,由于超类中这个方法没有抛出任何检查型异常,所以,你的paintComponent也不能抛出任何检查型异常。**如果类中的一个方法声明它会抛出一个异常,而这个异常是某个特定类的实例,那么这个方法抛出的异常可能属于这个类,也可能属于这个类的任意一个子类。**例如,
FileInputStream构造器声明有可能抛出一个IOException异常,在这种情况下,你并不知道具体是哪种IOException异常。它既可能是IOException,也可能是其某个子类的对象,例如,FileNotFoundException。
7.1.3 如何抛出异常
现在假设在程序代码中发生了糟糕的事情。一个名为 readData 的方法正在读取一个文件,文件首部承诺文件长度为 1024 个字符:
1 | |
不过,读到 733 个字符之后文件就结束了。你可能认为这是一种不正常的情况,希望抛出一个异常。
首先要决定应该抛出什么类型的异常。可能某种 IOException 是个不错的选择。仔细地阅读 Java API 文档之后会发现,EOFException 异常的描述是:“指示输入过程中意外遇到了 EOF”。完美,这正是我们要抛出的异常。可以如下抛出这个异常:
1 | |
或者,也可以写为:
1 | |
下面给出完整的代码:
1 | |
EOFException 类还有一个带一个字符串参数的构造器。你可以很好地利用这个构造器,更细致地描述异常情况。
1 | |
在前面已经看到,如果一个已有的异常类能够满足你的要求,抛出这个异常非常容易。在这种情况下:
- 找到一个合适的异常类。
- 创建这个类的一个对象。
- 将对象抛出。
一旦方法抛出了异常,这个方法就不会返回到调用者。也就是说,你不必操心建立一个默认的返回值或错误码。
7.1.4 创建异常类
你的代码可能会遇到任何标准异常类都无法描述清楚的问题。在这种情况下,创建自己的异常类就是一件顺理成章的事情了。我们要做的只是定义一个派生于 Exception 的类,或者派生于 Exception 的某个子类,如 IOException。习惯做法是,自定义的这个类应该包含两个构造器,一个是默认的构造器,另一个是包含详细描述信息的构造器(超类 Throwable 的 toString 方法会返回一个字符串,其中包含这个详细信息,这在调试中非常有用)。
1 | |
现在,就可以抛出你自己定义的异常类型了。
1 | |
7.2 捕获异常
7.2.1 捕获异常概述
如果发生了某个异常,但没有在任何地方捕获这个异常,程序就会终止,并在控制台上打印一个消息,其中包括这个异常的类型和一个栈轨迹。不过,图形用户界面(GUI)程序可能会捕获异常,打印栈轨迹消息,然后返回用户界面处理循环。(在调试 GUI 程序时,最好保证控制台窗口可见,并且没有最小化。)
要想捕获一个异常,需要建立 try/catch 语句块。最简单的 try 语句块如下所示:
1 | |
如果 try 语句块中的任何代码抛出了 catch 子句中指定的一个异常类,那么:
- 程序将跳过
try语句块的其余代码。 - 程序将执行
catch子句中的处理器代码。
如果 try 语句块中的代码没有抛出任何异常,那么程序将跳过 catch 子句。
如果方法中的任何代码抛出了一个异常,但不是 catch 子句中指定的异常类型,那么这个方法会立即退出(希望它的调用者为这种类型的异常提供了 catch 子句)。
为了展示捕获异常的过程,下面给出一个很典型的读取数据的代码:
1 | |
需要注意的是,try 子句中的大多数代码都很容易理解:读取并处理字节,直到遇到文件结束符为止。正如在 Java API 中看到的那样,read 方法有可能抛出一个 IOException 异常。在这种情况下,将跳出整个 while 循环,进入 catch 子句,并生成一个栈轨迹。对于一个“玩具类”的简单程序来说,这样处理异常看上去很有道理。还有其他的选择吗?
通常,最好的选择是什么也不做,而只是将异常继续传递给调用者。如果 read 方法出现了错误,就让 read 方法的调用者去操心这个问题!如果采用这种处理方式,就必须声明这个方法可能会抛出一个 IOException。
1 | |
请记住,编译器严格地执行 throws 说明符。如果调用了一个抛出检查型异常的方法,就必须处理这个异常,或者继续传递这个异常。
哪种方法更好呢?一般经验是,要捕获那些你知道如何处理的异常,而继续传播那些你不知道怎样处理的异常。
如果想传播一个异常,就必须在方法的首部添加一个 throws 说明符,提醒调用者这个方法可能会抛出一个异常。
查看 Java API 文档,可以看到每个方法可能会抛出哪些异常,然后再决定是由自己处理,还是添加到 throws 列表中。对于后一种选择,不用感到难堪。将异常交给胜任的处理器进行处理要比压制这个异常更好。
同时请记住,前面曾经提到过,这个规则有一个例外。如果编写一个覆盖超类方法的方法,而这个超类方法没有抛出异常(如 JComponent 中的 paintComponent),就必须捕获你的方法代码中出现的每一个检查型异常。子类的 throws 列表中不允许出现超类方法中未列出的异常类。
7.2.2 捕获多个异常
在一个 try 语句块中可以捕获多个异常类型,并对不同类型的异常做出不同的处理。要为每个异常类型使用一个单独的 catch 子句,如下例所示:
1 | |
异常对象可能包含有关异常性质的信息。要想获得这个对象的更多信息,可以尝试使用
1 | |
得到详细的错误消息(如果有的话),或者使用
1 | |
得到异常对象的实际类型。
**在 Java 7 中,同一个 catch 子句中可以捕获多个异常类型。**例如,假设对应缺少文件和未知主机异常的动作是一样的,就可以合并 catch 子句:
1 | |
只有当捕获的异常类型彼此之间不存在子类关系时才需要这个特性。
注释:**捕获多个异常时,异常变量隐含为
final变量。**例如,在以下子句体中不能为e赋一个不同的值:
catch (FileNotFoundException | UnknownHostException e) { ... }注释:捕获多个异常不仅会让你的代码看起来更简单,还会更高效。生成的字节码只包含对应公共
catch子句的一个代码块。
7.2.3 再次抛出异常与异常链
可以在 catch 子句中抛出一个异常。通常,希望改变异常的类型时会这样做。如果开发了一个供其他程序员使用的子系统,就可以使用一个指示子系统故障的异常类型,这很有道理。ServletException 就是这样一个异常类型的例子。执行一个 servlet 的代码可能不想知道发生错误的细节,但肯定希望知道这个 servlet 是否有问题。
可以如下捕获异常并将它再次抛出:
1 | |
在这里,构造 ServletException 时提供了异常的消息文本。
不过,还有一种更好的想法,可以把原始异常设置为新异常的“原因”:
1 | |
捕获到这个异常时,可以使用下面这条语句获取原始异常:
1 | |
强烈建议使用这种包装技术。这样可以在子系统中抛出高层异常,而不会丢失原始异常的细节信息。
提示:如果在一个方法中出现了一个检查型异常,但这个方法不允许抛出检查型异常,这种情况下包装技术也很有用。我们可以捕获这个检查型异常,并将它包装成一个运行时异常。
有时你可能只想记录一个异常,再将它重新抛出,而不做任何改变:
1 | |
在 Java 7 之前,这种方法存在一个问题。假设这个代码在以下方法中:
1 | |
Java 编译器查看 catch 块中的 throw 语句,然后查看 e 的类型,会指出这个方法可能抛出任何 Exception 而不只是 SQLException。现在这个问题已经得到改进。编译器会跟踪到 e 来自 try 块。假设这个 try 块中仅有的检查型异常是 SQLException 实例,另外假设 e 在 catch 块中未改变,将外围方法声明为 throws SQLException 就是合法的。
7.2.4 finally 子句
代码抛出一个异常时,就会停止处理这个方法中剩余的代码,并退出这个方法。如果这个方法已经获得了只有它自己才知道的一些本地资源,而这些资源必须清理,这就会有问题。一种解决方案是捕获所有异常,完成资源的清理,再重新抛出异常。但是,这种解决方案比较烦琐,因为需要在两个地方清理资源:一个是在正常的代码中,另一个是在异常代码中。finally 子句可以解决这个问题。
不管是否捕获到异常,finally 子句中的代码都会执行。在下面的示例中,所有情况下程序都将关闭输入流。
1 | |
下面来看这个程序执行 finally 子句的 3 种可能的情况:
代码没有抛出异常。
在这种情况下,程序首先执行
try语句块中的全部代码,然后执行finally子句中的代码。随后,继续执行finally子句之后的第一条语句。也就是说,执行的顺序是 1、2、5、6。代码抛出一个异常,并在一个
catch子句中捕获。在上面的示例中就是
IOException异常。在这种情况下,程序将执行try语句块中的所有代码,直到抛出异常为止。此时,将跳过try语句块中的剩余代码,转去执行与该异常匹配的catch子句中的代码,然后执行finally子句中的代码。- 如果
catch子句没有抛出异常,程序将执行finally子句之后的第一条语句。在这种情况下,执行顺序是 1、3、4、5、6。 - 如果
catch子句抛出了一个异常,异常将被抛回到这个方法的调用者。执行顺序则只是 1、3、5。
- 如果
代码抛出了一个异常,但没有任何
catch子句捕获这个异常。在这种情况下,程序将执行
try语句块中的所有语句,直到抛出异常为止。此时,将跳过try语句块中的剩余代码,然后执行finally子句中的语句,并将异常抛回给这个方法的调用者。在这里,执行顺序只是 1、5。
**try 语句可以只有 finally 子句,而没有 catch 子句。**例如,下面这条 try 语句:
1 | |
无论在 try 语句块中是否遇到异常,finally 子句中的 in.close() 语句都会执行。当然,如果真的遇到一个异常,这个异常将会被重新抛出,并且必须由另一个 catch 子句捕获。
1 | |
内层的 try 语句块只有一个职责,就是确保关闭输入流。外层的 try 语句块也只有一个职责,就是确保报告出现的错误。这种解决方案不仅更清楚,而且功能更强:将会报告 finally 子句中出现的错误。
[!WARNING]
当
finally子句包含return语句时,有可能产生意想不到的结果。假设由return语句从try语句块中间退出。在方法返回前,会执行finally子句块。**如果finally块也有一个return语句,这个返回值将会遮蔽原来的返回值。**来看下面这个例子:
2
3
4
5
6
7public static int parseInt(String s) {
try {
return Integer.parseInt(s);
} finally {
return 0; // ERROR
}
}看起来在
parseInt("42")调用中,try块的体会返回整数 42。不过,这个方法真正返回之前,会执行finally子句,这就使得方法最后会返回 0,而忽略原先的返回值。更糟糕的是,考虑调用
parseInt("zero")。Integer.parseInt方法会抛出一个NumberFormatException,然后执行finally子句,return语句甚至“吞掉”了这个异常!
finally子句的体要用于清理资源。不要把改变控制流的语句(return、throw、break、continue)放在finally子句中。
7.2.5 try-with-Resources 语句
在 Java 7 中,对于以下代码模式:
1 | |
假设这个资源属于一个实现了 AutoCloseable 接口的类,Java 7 为这种代码模式提供了一个很有用的快捷方式。AutoCloseable 接口有一个方法:
1 | |
[!NOTE]
注释:另外,还有一个
Closeable接口。这是AutoCloseable的子接口,也只包含一个close方法。不过,这个方法声明为抛出一个IOException。
try-with-resources 语句(带资源的 try 语句)的最简形式为:
1 | |
try 块退出时,会自动调用 res.close()。下面给出一个典型的例子,这里要读取一个文件中的所有单词:
1 | |
这个块正常退出时,或者存在一个异常时,都会调用 in.close() 方法,就好像使用了 finally 块一样。
还可以指定多个资源。例如:
1 | |
不论这个块如何退出,in 和 out 都会关闭。如果用常规方式手动编程,就需要两个嵌套的 try/finally 语句。
在 Java 9 中,可以在 try 首部提供之前声明的事实最终变量:
1 | |
如果 try 块抛出一个异常,而且 close 方法也抛出一个异常,这就会带来一个难题。try-with-resources 语句可以很好地处理这种情况。原来的异常会重新抛出,而 close 方法抛出的所有异常会“被抑制”。这些异常将被自动捕获,并由 addSuppressed 方法添加到原来的异常中去。如果对这些异常感兴趣,可以调用 getSuppressed 方法,它会生成一个数组,其中包含从 close 方法抛出的被抑制的异常。
你肯定不想手动编程来处理这些问题。只要需要关闭资源,就要尽可能使用 try-with-resources 语句。
[!NOTE]
注释:
try-with-resources语句自身也可以有catch子句,甚至还可以有一个finally子句。这些子句会在关闭资源之后执行。
7.2.6 分析栈轨迹元素
**栈轨迹(stack trace)**是程序执行过程中某个特定点上所有挂起的方法调用的一个列表。你肯定已经看到过这种栈轨迹列表,当 Java 程序因为一个未捕获的异常而终止时,就会显示栈轨迹。
可以调用 Throwable 类的 printStackTrace 方法访问栈轨迹的文本描述信息。
1 | |
一种更灵活的方法是使用 StackWalker 类,它会生成一个 StackWalker.StackFrame 实例流,其中每个实例分别描述一个栈帧(stack frame)。可以利用以下调用迭代处理这些栈帧:
1 | |
如果想要以懒方式处理 Stream<StackWalker.StackFrame>,可以调用:
1 | |
StackWalker.StackFrame 类有一些方法可以得到正在执行的代码行的文件名和行号,以及类对象和方法名。toString 方法会生成一个格式化字符串,其中包含所有这些信息。
[!NOTE]
注释:在 Java 9 之前,
Throwable.getStackTrace方法会生成一个StackTraceElement[]数组,其中包含与StackWalker.StackFrame实例流类似的信息。不过,这个调用的效率不高,因为它要得到整个栈,即使调用者可能只需要几个栈帧。另外它只允许访问挂起方法的类名,而不能访问类对象。
7.3 使用异常的技巧
关于如何适当地使用异常还有很大的争议。有些程序员认为所有检查型异常都令人厌恶,也有些程序员认为抛出的异常还不够多。我们认为异常(甚至是检查型异常)还是有其存在的意义。下面给出适当使用异常的一些技巧。
- 异常处理不能代替简单的测试
作为一个示例,假设有一段代码尝试将一个空栈弹出 10 000 000 次。第一种做法是:首先查看栈是否为空。
1 | |
再看第二种做法,我们强制要求不管怎样都执行弹出操作,然后捕获 EmptyStackException 异常来告诉我们不该这样做。
1 | |
在我的测试机器上,调用 isEmpty 的版本运行时间为 646 毫秒。捕获 EmptyStackException 的版本运行时间为 21 739 毫秒。
可以看出,与完成简单的测试相比,捕获异常所花费的时间大大超过了前者,因此使用异常的基本规则是:只在异常情况下使用异常。
- 不要过分地细化异常
很多程序员将每一条语句都分装在一个单独的 try 语句块中。
1 | |
这种编程方式将导致代码量的急剧膨胀。首先来看你希望这段代码完成的任务。在这里,我们希望从栈中弹出 100 个数,将它们存入一个文件中。如果出现问题,我们什么也做不了。如果栈是空的,它不会变成非空状态;如果文件包含错误,这个错误也不会神奇地消失。因此,合理的做法是将整个任务包在一个 try 语句块中,这样,当任何一个操作出现问题时,就可以取消整个任务。
1 | |
这段代码看起来清晰多了。这样也满足了异常处理的一个承诺:将正常处理与错误处理分开。
- 合理利用异常层次结构
不要只抛出 RuntimeException 异常。应该寻找一个适合的子类或创建你自己的异常类。
不要只捕获 Throwable 异常,否则,这会使你的代码很难读、很难维护。
考虑检查型异常与非检查型异常的区别。检查型异常本质上开销较大,不要为逻辑错误抛出这些异常。(例如,反射库的做法就不正确。调用者经常需要捕获那些他们知道不可能发生的异常。)
如果能够将一种异常转换成另一种更加适合的异常,那么不要犹豫。例如,在解析某个文件中的一个整数时,可以捕获 NumberFormatException 异常,然后将它转换成 IOException 的一个子类或 MySubsystemException。
- 不要压制异常
在 Java 中,往往非常希望关闭异常。如果你编写了一个方法要调用另一个方法,而那个方法有可能 100 年才抛出一个异常,但是,如果没有在你的方法的 throws 列表中声明这个异常,编译器就会报错。你不想把它放在 throws 列表中,因为这样一来,编译器会对调用你的方法的所有方法都报错。因此,你会关闭这个异常:
1 | |
现在你的代码可以顺利通过编译了。它能很好地运行,除非出现异常。然后这个异常会被悄无声息地忽略。如果你认为异常都非常重要,就应该适当地进行处理。
在检测错误时,“苛刻”要比放任更好
检测到错误的时候,有些程序员对抛出异常很担心。调用一个方法时,如果提供了非法的参数,返回一个虚拟值是不是比抛出一个异常更好?例如,当栈为空时,Stack.pop是该返回null,还是要抛出一个异常?我们认为:最好在出错的地方抛出一个EmptyStackException异常,这要好于以后出现一个NullPointerException异常。不要羞于传递异常
很多程序员感觉应该捕获抛出的全部异常。如果他们调用了一个抛出异常的方法,例如,FileInputStream构造器或readLine方法,他们就会本能地捕获可能产生的异常。其实,很多时候,更好的做法是继续传递这个异常,而不是自己捕获:
1 | |
更高层的方法通常可以更好地通知用户发生了错误,或者放弃不成功的命令。
(注释:规则 5、6 可以归纳为“早抛出,晚捕获”。)
- 使用标准方法报告
null指针和越界异常Objects包含以下方法:
requireNonNullcheckIndexcheckFromToIndexcheckFromIndexSize
来完成这些常见的检查。要用这些方法来完成参数检验:
1 | |
如果调用方法时提供了一个非法索引或一个 null 参数,要用我们熟悉的 Java 库使用的消息抛出一个异常。
- 不要向最终用户显示栈轨迹
如果你的程序遇到一个预料之外的异常,看起来显示一个栈轨迹是个好主意,这样用户就能报告这个错误,使你能更容易地找出问题所在。不过,栈轨迹可能包含你不想暴露给潜在攻击者的实现细节,例如你使用的库的版本。
应该将栈轨迹记入日志,以便以后获取,而只向用户显示一个总结消息。
7.4 使用断言
在一个具有自我保护能力的程序中,断言很常用。
7.4.1 断言的概念
假设你确信满足某个特定属性,并且代码依赖于这个属性。例如,可能需要计算:
1 | |
你确信这里的 x 是一个非负数。原因可能是:x 是另外一个计算的结果,而这个计算的结果不可能为负;或者 x 是一个方法的参数,这个方法要求它的调用者只能提供一个正数输入。不过,你可能还是想再做一次检查,不希望计算中潜入让人困惑的“不是一个数”(NaN)浮点值。当然,也可以抛出一个异常:
1 | |
即使测试完成后,这个测试代码还一直保留在程序中。如果在程序中含有大量这种检查,程序运行起来会比应有的速度慢一些。
**断言(assertion)**机制允许你在测试期间在代码中插入一些检查,而在生产代码中自动删除这些检查。
Java 语言有一个关键字 assert。这个关键字有两种形式:
1 | |
和
1 | |
这两个语句都会计算条件(condition),如果结果为 false,则抛出一个 AssertionError 异常。在第二个语句中,表达式(expression)将传入 AssertionError 对象的构造器,并转换成一个消息字符串。
注释:表达式(expression)部分的唯一目的是生成一个消息字符串。
AssertionError对象并不存储具体的表达式值,因此,以后无法得到这个表达式值。正如 Java 文档所描述的那样:如果能得到表达式的值,“就会鼓励程序员尝试从断言失败恢复,这有违于断言机制的初衷”。
要想断言 x 是一个非负数,只需要使用下面这条语句:
1 | |
或者将 x 的具体值传递给 AssertionError 对象,以便以后显示:
1 | |
7.4.2 启用和禁用断言
**在默认情况下,断言是禁用的。**可以在运行程序时用 -enableassertions 或 -ea 选项启用断言:
1 | |
需要注意的是,不必重新编译程序来启用或禁用断言。**启用或禁用断言是类加载器(class loader)的功能。**禁用断言时,类加载器会去除断言代码,因此,不会降低程序运行的速度。
甚至可以在特定的类或整个包中启用断言,例如:
1 | |
这条命令将为 MyClass 类以及 com.mycompany.mylib 包及其子包中的所有类打开断言。选项 -ea 将为无名包中的所有类打开断言。
也可以用选项 -disableassertions 或 -da 在特定的类和包中禁用断言:
1 | |
有些类不是由类加载器加载,而是直接由虚拟机加载。可以使用这些开关有选择地启用或禁用那些类中的断言。
不过,启用和禁用所有断言的 -ea 和 -da 开关不能应用于那些没有类加载器的“系统类”。需要使用 -enablesystemassertions / -esa 开关启用系统类中的断言。
也可以通过编程控制类加载器的断言状态。
7.4.3 使用断言完成参数检查
在 Java 语言中,提供了 3 种处理系统错误的机制:
- 抛出一个异常
- 记录日志
- 使用断言
什么时候应该选择使用断言呢?请记住下面几点:
- 断言失败是致命的、不可恢复的错误。
- 断言检查只在开发和测试阶段打开(这种做法有时候被戏称为“在靠近海岸时穿上救生衣,但在海里就把救生衣抛掉”)。
因此,不应该使用断言向程序的其他部分通知发生了可恢复性的错误,或者,不应该利用断言与程序用户沟通问题。断言只应该用于在测试阶段确定程序内部错误的位置。
下面看一个常见的场景:检查方法的参数。是否应该使用断言来检查非法的索引值或 null 引用呢?要想回答这个问题,首先来看这个方法的文档。假设你要实现一个排序方法。
1 | |
文档指出,如果索引值不正确,这个方法会抛出一个异常。这是方法与其调用者之间约定的行为。如果实现这个方法,那就必须要遵守这个约定,抛出表示索引值有误的异常。这里使用断言不太合适。
是否应该断言 a 不是 null 呢?这也不太合适。这个方法的文档没有指出当 a 是 null 时应该采取什么行为。在这种情况下,调用者可以认为这个方法将会成功地返回,而不会抛出一个断言错误。
不过,假设对这个方法的约定做一点微小的改动:
1 | |
现在,这个方法的调用者就必须注意:对 null 数组调用这个方法是不合法的。这样一来,就可以在这个方法的开头使用断言:
1 | |
计算机科学家将这种约定称为前置条件(Precondition)。原先的方法对参数没有前置条件,它承诺在任何情况下都有明确的行为。修改后的方法有一个前置条件,即 a 非 null。如果调用者没有满足这个前置条件,断言会失败,这个方法就能“为所欲为”。事实上,由于有这个断言,当方法被非法调用时,它的行为将是难以预料的。有时候会抛出一个断言错误,有时候会产生一个 null 指针异常,这完全取决于它的类加载器如何配置。
7.4.4 使用断言提供假设文档
通常,很多程序员使用注释来提供底层假设的文档。考虑 Oracle 官方文档 上的一个示例:
1 | |
在这种情况下,使用断言会更合适。
1 | |
当然,更好的做法是全面地考虑这个问题。i % 3 的值会是什么?如果 i 是正值,那么余数肯定是 0、1 或 2。如果 i 是负值,余数可以是 -1 和 -2。因此,真正的假设是 i 是非负值。最好是在语句之前使用以下断言:
1 | |
无论如何,这个示例说明了程序员应该充分使用断言来进行自我检查。你会看到,断言是一种用于测试和调试的战术性工具;与之不同,日志是一种用于程序整个生命周期的战略性工具。
7.5 日志
每个 Java 程序员都很熟悉在有问题的代码中插入一些 System.out.println 方法调用来帮助观察程序的行为。当然,一旦发现问题的根源,就要将这些 print 语句从代码中删去。如果接下来又出现了问题,只好再插入几个 print 语句。日志 API 就是为了解决这个问题而设计的。
下面先讨论这个 API 的主要优点:
可以很容易地抑制全部日志记录,或者只抑制某个级别以下的日志,而且再次打开这些日志也很容易。
被抑制的日志开销低廉,因此,将这些日志代码留在应用中只有很小的开销。
日志记录可以定向到不同的处理器,如在控制台显示、写至文件,等等。
日志记录器和处理器都可以对记录进行过滤。过滤器可以根据实现过滤器的程序员提供的标准丢弃那些无用的日志记录。
日志记录可以采用不同的方式格式化,例如,纯文本或 XML。
应用程序可以使用多个日志记录器,它们使用与包名类似的有层次的名字,例如,
com.mycompany.myapp。日志系统的配置由配置文件控制。
注释:很多应用会使用其他日志框架,如 Log4J 2 和 Logback,它们能提供比标准 Java 日志框架更高的性能。这些框架的 API 稍有区别。SLF4J 和 Commons Logging 等日志门面(Logging Facades)提供了一个统一的 API,利用这个 API,你无须重写应用就可以替换日志框架。让人更混乱的是,Log4J 2 也可以作为使用 SLF4J 的组件的门面。
在本书中,我们只介绍标准 Java 日志框架。对于很多用途来说,这个框架已经足够好,而且学习这个框架的 API 也可以让你做好准备去理解其他框架。
注释:在 Java 9 中,Java 平台有一个单独的轻量级日志系统,它不依赖于
java.logging模块(这个模块包含标准 Java 日志框架)。这个系统只用于 Java API。如果有java.logging模块,日志消息会自动地转发给它。第三方日志框架可以提供适配器来接收平台日志消息。我们不打算介绍平台日志,因为开发应用程序的程序员不太会用到平台日志。
7.5.1 基本日志
对于简单的日志记录,可以使用**全局日志记录器(global logger)**并调用其 info 方法:
1 | |
在默认情况下,会如下打印这个记录:
1 | |
但是,如果在适当的地方(如 main 的最前面)调用:
1 | |
将会抑制所有日志。
7.5.2 高级日志
既然已经了解了基本日志,下面再来看更高级的专业级日志。在一个专业的应用程序中,你肯定不想将所有的日志都记录到一个全局日志记录器中。你可以定义自己的日志记录器。
可以调用 getLogger 方法创建或获取一个日志记录器:
1 | |
[!NOTE]
提示:未被任何变量引用的日志记录器可能会被垃圾回收。为了防止这种情况发生,要像上面的例子中一样,用静态变量存储日志记录器的一个引用。
与包名类似,日志记录器名也有层次。事实上,与包相比,日志记录器的层次性更强。对于包来说,包与父包之间没有语义关系,但是日志记录器的父与子之间会共享某些属性。例如,如果对日志记录器 "com.mycompany" 设置了日志级别,它的子日志记录器也会继承这个级别。
通常,有以下 7 个日志级别:
- SEVERE
- WARNING
- INFO
- CONFIG
- FINE
- FINER
- FINEST
在默认情况下,实际上只记录前 3 个级别。也可以设置一个不同的级别,例如:
1 | |
现在,会记录 FINE 以及所有更高级别的日志。
另外,还可以使用 Level.ALL 开启所有级别的日志记录,或者使用 Level.OFF 关闭所有日志。
所有级别都有日志记录方法,如:
1 | |
或者,还可以使用 log 方法并指定级别,例如:
1 | |
提示:默认的日志配置会记录 INFO 或更高级别的所有日志,因此,对于那些有助于诊断但对用户意义不大的调试信息,应该使用 CONFIG、FINE、FINER 和 FINEST 级别。
警告:如果将记录级别设置为比 INFO 更低的级别,还需要修改日志处理器的配置。默认的日志处理器会抑制低于 INFO 级别的消息。
默认的日志记录会显示包含日志调用的类和方法的名字(根据调用栈得出)。不过,如果虚拟机对执行过程进行了优化,就可能得不到准确的调用信息。此时,可以使用 logp 方法获得调用类和方法的确切位置,这个方法的签名为:
1 | |
有一些用来跟踪执行流的便利方法:
1 | |
例如:
1 | |
这些调用将生成 FINER 级别而且以字符串 ENTRY 和 RETURN 开头的日志记录。
[!NOTE]
注释: 在将来某个时候,带
Object参数的日志记录方法可能会被重写,以支持可变参数列表(“ varargs ”)。那时就可以做出类似
logger.entering("com.mycompany.mylib.Reader", "read", file, pattern)的调用了。
记录日志的一个常见用途是记录那些预料之外的异常。可以使用下面两个便利方法在日志记录中包含异常的描述:
1 | |
典型的用法是:
1 | |
和
1 | |
throwing 调用可以记录一条 FINER 级别的日志记录和一个以 THROW 开头的消息。
7.5.3 修改日志管理器配置
可以通过编辑配置文件来修改日志系统的各个属性。默认的配置文件位于:
jdk/conf/logging.properties(或者在 Java 9 之前,位于 jre/lib/logging.properties。)
要想使用另一个配置文件,就要将 java.util.logging.config.file 属性设置为那个文件的位置,为此要用以下命令启动你的应用程序:
1 | |
要想修改默认的日志级别,需要编辑配置文件,并修改下面这行设置:
1 | |
可以为你自己的日志记录器指定日志级别,例如,可以增加下面这行设置:
1 | |
也就是说,在日志记录器名后面追加后缀 .level。
稍后可以看到,日志记录器并不将消息发送到控制台,那是处理器的任务。处理器也有级别。要想在控制台上看到 FINE 级别的消息,就需要如下设置:
1 | |
[!NOTE]
警告: 日志管理器配置中的属性设置不是系统属性,因此,用
-Dcom.mycompany.myapp.level=FINE启动程序不会对日志记录器产生任何影响。
日志管理器在虚拟机启动时初始化,也就是在 main 方法执行前。如果想要定制日志属性,但是没有用
-Djava.util.logging.config.file
命令行选项启动应用,可以在程序中调用:
1 | |
不过,这样一来,你还必须调用:
1 | |
重新初始化日志管理器。
在 Java 9 中,可以通过调用以下方法更新日志配置:
1 | |
这样就会从 java.util.logging.config.file 系统属性指定的位置读取一个新配置。然后应用这个映射器来解析新老配置中所有键的值。映射器是一个:
1 | |
它将现有配置中的键映射到替换函数。每个替换函数接收到与键关联的老值和新值(或者,如果没有关联的值则得到 null),生成一个替换,或者如果要在更新中删除这个键则返回 null。
这听起来相当复杂,所以我们来看几个例子。
一种很有用的映射机制是合并老配置和新配置,如果一个键在老配置和新配置中都出现,则优先选择新值。这样一个**映射器(mapper)**就是:
1 | |
或者你可能只想更新以 com.mycompany 开头的键,而其他的键保持不变:
1 | |
还可以使用 jconsole 程序改变一个正在运行的程序的日志级别。有关的信息参见:
https://www.oracle.com/technetwork/articles/java/jconsole-1564139.html#LoggingControl
[!NOTE]
注释:日志属性文件由
java.util.logging.LogManager类处理。可以通过将java.util.logging.manager系统属性设置为某个子类的名字来指定一个不同的日志管理器。或者,可以保留标准日志管理器,而绕过从日志属性文件初始化。可以将java.util.logging.config.class系统属性设置为某个类名,该类再以另外某种方式设置日志管理器属性。有关的更多信息请参见LogManager类的 API 文档。
7.5.4 本地化
下面简要说明本地化日志消息时需要牢记的一些要点。
本地化的应用程序包含资源包(resource bundle)中的本地特定信息。资源包包括一组映射,分别对应各个本地化环境(如美国或德国)。例如,一个资源包可能将字符串 "readingFile" 映射为英文的 "Reading file" 或者德文的 "Achtung! Datei wird eingelesen"。
一个程序可以包含多个资源包,例如一个用于菜单,另一个用于日志消息。每个资源包都有一个名字(如 "com.mycompany.logmessages")。要想为资源包增加映射,需要对应每个本地化环境提供一个文件。英文消息映射位于:
1 | |
德文消息映射位于:
1 | |
(en 和 de 是语言编码。)可以将这些文件与应用程序的类文件放在一起,以便 ResourceBundle 类自动找到它们。这些文件都是纯文本文件,包含如下所示的条目:
1 | |
请求一个日志记录器时,可以指定一个资源包:
1 | |
然后,为日志消息指定资源包的键,而不是具体的日志消息字符串:
1 | |
通常需要在本地化的消息中包含一些参数,因此,消息可以包括占位符 {0}、{1} 等。例如,要想在日志消息中包含文件名,可以如下使用占位符:
1 | |
然后,通过调用下面的一个方法向占位符传递具体的值:
1 | |
或者,在 Java 9 中,可以在 logrb 方法中指定资源包对象(而不是名字):
1 | |
[!NOTE]
注释: 这是唯一一个可以为消息参数使用可变参数的日志记录方法。
7.5.5 处理器
在默认情况下,日志记录器将记录发送到 ConsoleHandler,它会将记录输出到 System.err 流。具体地,日志记录器会把记录发送到父处理器,而最终的祖先处理器(名为 “”)有一个 ConsoleHandler。
与日志记录器一样,处理器也有日志级别。对于一个要记录的日志记录,它的日志级别必须高于日志记录器和处理器二者的阈值。日志管理器配置文件将默认的控制台处理器的日志级别设置为
1 | |
要想记录 FINE 级别的日志,就必须修改配置文件中的默认日志记录器级别和处理器级别。或者,还可以绕过配置文件,安装你自己的处理器。
1 | |
在默认情况下,日志记录器将记录发送到自己的处理器和父日志记录器的处理器。我们的日志记录器是祖先日志记录器(名为 “”)的子类,而这个祖先日志记录器会把所有等于或高于 INFO 级别的记录发送到控制台。不过,我们并不想两次看到这些记录,因此应该将 useParentHandlers 属性设置为 false。
要想将日志记录发送到其他地方,就要添加其他的处理器。日志 API 为此提供了两个很有用的处理器,一个是 FileHandler,另一个是 SocketHandler。SocketHandler 将记录发送到指定的主机和端口。而更令人感兴趣的是 FileHandler,它可以将记录收集到一个文件中。
可以如下直接将记录发送到默认文件处理器:
1 | |
这些记录被发送到用户主目录的 java0.log 文件中,n 是保证文件唯一的一个编号。如果用户系统没有主目录的概念(例如,在 Windows 95/98/ME 中),文件就存储在一个默认位置(如 C:\Windows)。默认情况下,记录会格式化为 XML。一个典型的日志记录形式如下:
可以通过设置日志管理器配置文件中的不同参数(请参见表 7-1),或者使用另一个构造器来修改文件处理器的默认行为。
以下文本完全按照你提供的图片格式(含段落、表7-2、提示框等)逐行提取,未增删空格与标点:
也有可能不想使用默认的日志文件名,因此,应该使用另一种模式,例如,
%h/myapp.log(有关模式变量的解释请参见表 7-2)。

如果多个应用程序(或者同一个应用程序的多个副本)使用同一个日志文件,就应该打开 append 标志。或者,应该在文件名模式中使用 %u,这样每个应用程序会创建日志的唯一副本。
打开文件循环功能也是一个不错的主意。日志文件以循环序列的形式保存(如 myapp.log, myapp.log.1, myapp.log.2 等)。只要文件超出了大小限制,最老的文件就会被删除,其他的文件将重新命名,同时创建一个新文件,其生成编号为 0。
提示:很多程序员将日志记录作为辅助文档提供给技术支持人员。如果程序的行为有误,用户可以发回日志文件来查看原因。在这种情况下,应该打开 append 标志,或者使用循环日志,也可以二者同时使用。
还可以通过扩展 Handler 类或 StreamHandler 类自定义处理器。在本节末尾的示例程序中就定义了这样一个处理器。这个处理器将在一个窗口中显示日志记录(如图 7-2 所示)。
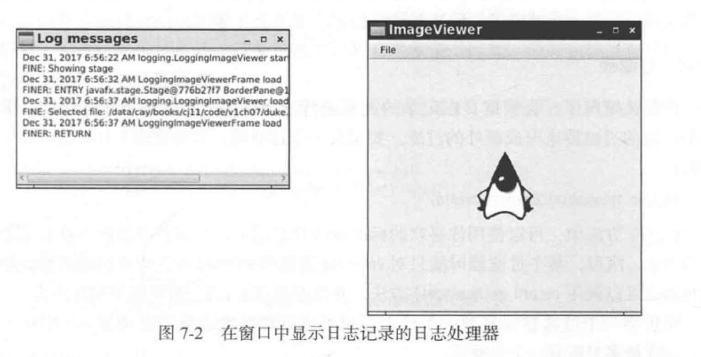
这个处理器扩展了 StreamHandler 类,并安装了一个流,这个流的 write 方法将流输出显示到一个文本区中。
1 | |
使用这种方式只有一个问题,这就是处理器会缓存记录,并且只有在缓冲区满的时候才将它们写入流中。因此,需要覆盖 publish 方法,使得处理器获得每个记录之后就会刷新输出缓冲区。
1 | |
如果希望编写更加复杂的流处理器,可以扩展 Handler 类,并定义 publish、flush 和 close 方法。
7.5.6 过滤器
在默认情况下,会根据日志记录的级别进行过滤。每个日志记录器和处理器都可以有一个可选的过滤器来完成额外的过滤。要定义一个过滤器,需要实现 Filter 接口并定义以下方法:
1 | |
在这个方法中,可以使用你喜欢的标准分析日志记录,对那些应该包含在日志中的记录返回 true。例如,某个过滤器可能只对 entering 方法和 exiting 方法生成的消息感兴趣,这个过滤器就可以调用 record.getMessage() 方法,并检查消息是否以 ENTRY 或 RETURN 开头。
要想将一个过滤器安装到一个日志记录器或处理器中,只需要调用 setFilter 方法。注意,一次最多只能有一个过滤器。
7.5.7 格式化器
ConsoleHandler 类和 FileHandler 类可以生成文本和 XML 格式的日志记录。不过,你也可以自定义格式。这需要扩展 Formatter 类并覆盖下面这个方法:
1 | |
可以用你喜欢的任何方式对记录中的信息进行格式化,并返回结果字符串。在 format 方法中,可能会调用下面这个方法:
1 | |
这个方法对记录中的消息部分进行格式化,将替换参数并应用本地化处理。
很多文件格式(如 XML)需要在已格式化的记录的前后加上一个头部和尾部。为此,要覆盖下面两个方法:
1 | |
最后,调用 setFormatter 方法将格式化器安装到处理器中。
7.5.8 日志技巧
面对日志记录如此之多的选项,很容易让人忘记了最基本的东西。下面的技巧总结了一些最常用的操作。
- 对一个简单的应用,选择一个日志记录器。可以把日志记录器命名为与主应用包同名,例如,
com.mycompany.myprog,这是一个好主意。总是可以通过以下调用得到日志记录器:
1 | |
为方便起见,你可能希望为有大量日志记录活动的类增加静态字段:
以下文本完全依照图片中的缩进、换行、代码段及注释格式逐字提取,未增删任何字符:
1 | |
- 默认的日志配置会把级别等于或高于 INFO 的所有消息记录到控制台。用户可以覆盖这个默认配置。但是正如前面所述,改变配置的过程有些复杂。因此,最好在你的应用中安装一个更合适的默认日志处理器。
以下代码确保将所有的消息记录到应用特定的一个文件中。可以将这段代码放置在应用程序的 main 方法中。
1 | |
- 现在,可以记录自己想要的内容了。需要牢记:所有级别为 INFO、WARNING 和 SEVERE 的消息都将显示到控制台上。因此,要记录对程序用户有意义的消息,可以使用这几个级别。
对于程序员想要的日志消息,FINE 级别是一个很好的选择。
想要调用 System.out.println 时,可以换成发出以下日志消息:
1 | |
记录那些预料之外的异常也是一个不错的想法,例如:
1 | |